v2.0->v2.1 增加来源出土文献的人名、释义反查、性能优化



增加来源出土文献的人名、释义反查、性能优化。
对于此前版本 IDS 信息的加载不全及生僻字字体的选用问题,特此感谢黄俊亮的提示与建议。
1. 姓名数据
增加吐蕃人名、新疆出土汉晋简牍人名、走马楼吴简第九卷人名。
- 吐蕃人名来自黄布凡、马德《敦煌藏文吐蕃史文献译注》 所附人名索引,总共录入362个人名,切分为69个姓氏(不重复计次,包括无姓)、名字中95个整体构件、155个构件一、184个构件二。除了“可敦”是突厥人称呼,其它都标注为吐蕃人名。书中汉族、南诏、尼泊尔等人名未录,也并未考虑吐蕃姓氏与身份的关联。吐蕃人名较长,能切分的名字尽量对照音节和意思(如有)切成了两部分,切作两份是为了保持整体姓名处理方式的兼容性,有更好的做法,不过目前这样效果尚可。
- 新疆出土汉晋简牍人名来自韩厚明《新疆出土汉晋简牍集释》中的人名索引表,合计301个人名,魏晋281个,两汉20个,两汉的不多,所以不做时期拆分。魏晋时期的简牍记录有记姓不记名的做法,与汉简有所不同,但结合姓氏用字与简文内容,容易区分。
- 走马楼吴简系列丛书的第九卷,所处时期基本是整齐一致的单名。该丛书有很多卷,优先录这卷,一是因为篇幅较短,二是第五卷和第九卷网上没有,这是我去图书馆拍的。
西域其余的汉文与非汉文出土文书的人名,没有资源和时间,所以人名标注将长期或者永远处于 beta 版。
东周人名可能可以加入,但短期之内不会更新。
2. 基础功能
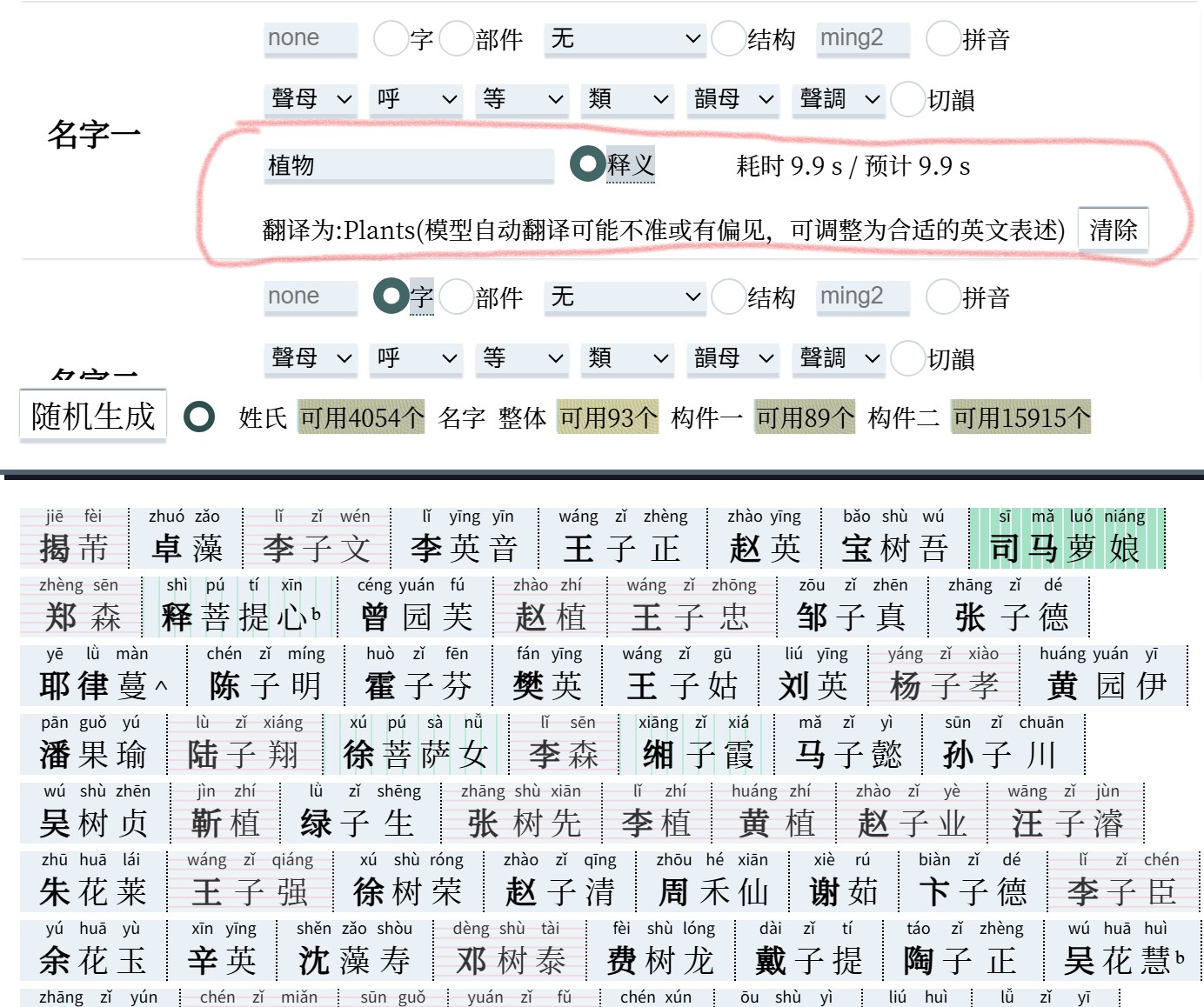
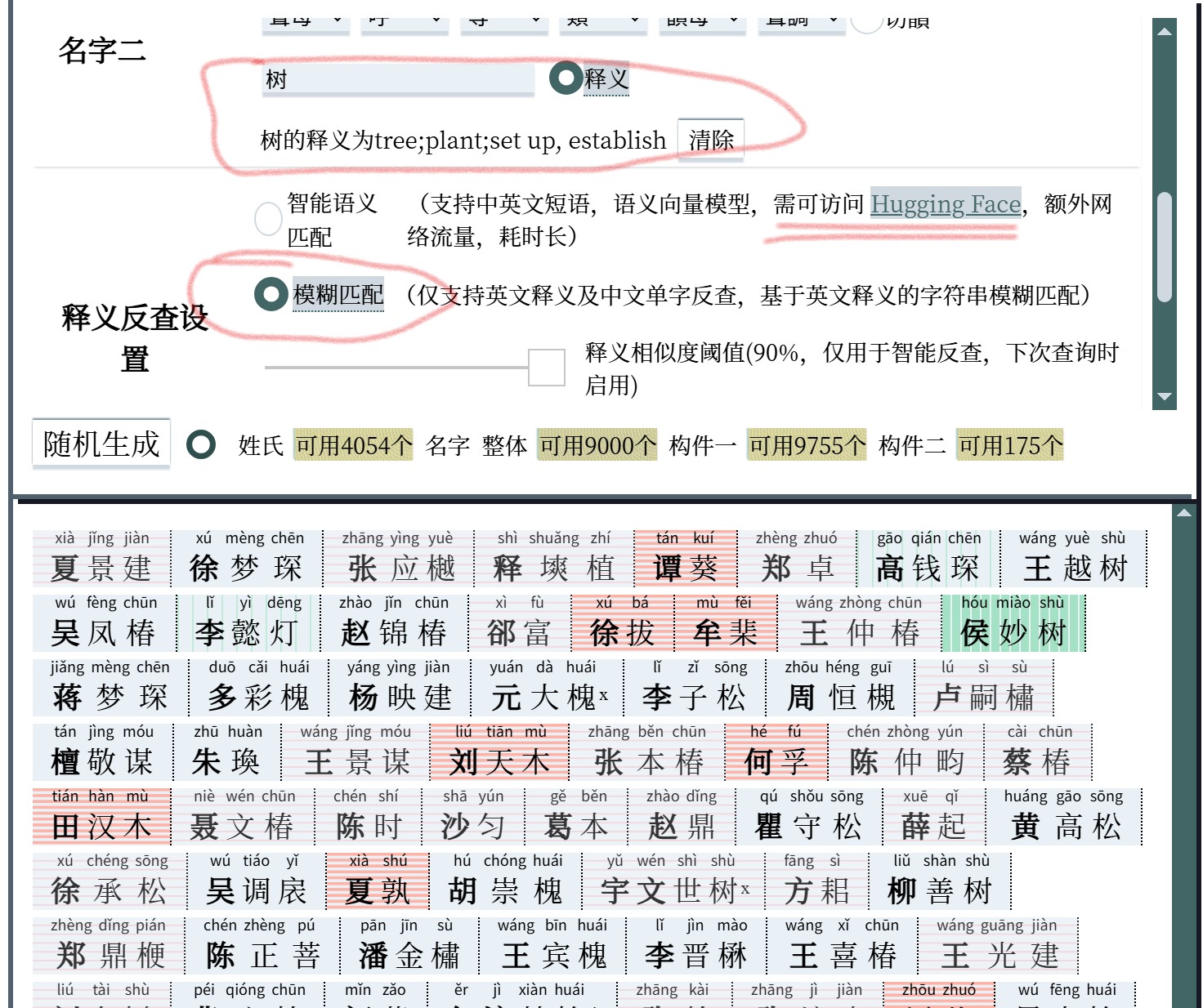
增加释义反查,释义反查有两种模式:智能语义匹配、字符串模糊匹配。注意:输入释义后,鼠标点击或触屏点击输入框外部的其它区域,退出聚焦输入框的状态后才会启动查询。
- 智能语义匹配。使用语义向量模型、基于英文释义构建的匹配功能,支持中英文短语。输入中文将自动识别并翻译为英文。预处理数据集与程序均部署在 Hugging Face,基于地区限制可能需要设置网络代理。消耗额外的网络流量,耗时长。长期无人使用,该功能将处于睡眠状态,如能正常访问,请先发起一次查询请求等待功能被唤醒,或在 Hugging Face 页面唤醒该功能。
模型完全基于语义,能够理解并处理:“豪放不羁”、“新生的植物”、“某某、某某和某某”、“某某或某某或某某”等语义,或者说是意象,并返回语义接近的字。但不能处理词性的限定(“动词、名词”);也不能准确理解或者过于佶屈聱牙的表述,如“渊懿美茂”;也不要添加与释义无关的内容,全部翻译结果都会参与近似度匹配,如“请为我返回与鸟类有关的用字”,会匹配释义与全句“Please return to the bird-related words for me”而非与 bird 类似的用字。
程序内已做了针对模型主观倾向或偏见的预处理与后处理,但模型自动翻译可能仍然不准或有偏见。如输入中文,可在查看返回的翻译结果后,调整为合适的英文表述。
该功能的一个副产品是:古汉语语义关系图谱。
- 基于英文释义的字符串模糊匹配。仅支持英文释义及中文单字反查。使用 Fuse.js 实现英文释义的模糊匹配查询。部署在网页内,即时返回,但字符串近似度与语义近似度有所区别,亦需要用户具有适应此版本所用英文释义(Unihan与《上古汉语新构拟》词表)的、较好的英文概括能力。
3. 性能优化
增加拼音显示,拼音功能由第三方 js 库 pinyin-pro 提供(包含姓氏读音判断)。语言设置为英文时,同步勾选概览区的拼音标注;也可以在配置 > 标注拼音处手动勾选。 修复了开屏logo懒加载的问题。
修复了没有载入全部IDS信息的问题,改为直接读入ids_lv2.txt。
修复了收藏夹菜单栏总是被翻译成英文的问题。 修复了切韵注音选择为“msoeg 擬音 V8” 时有时因设置而不能正常加载详情页的问题。
优化详情页展示,具体优化了哪里忘记了。
考虑到出土文献中大量Unicode CJK扩展区汉字的存在,对这些生僻字设置文津宋体作为fallback字体(备用字体),应能解决手机设备上缺乏全字库字体而将这部分字显示为□的问题。为保持风格一致,同步修改原来的主要字体Noto Sans(黑体)为 Noto Serif(宋体)。网页中加载的是文津宋体在扩展区的子集,常见汉字仍渲染为 Noto Serif。
Files
Get 古代人名生成器: Ancient Chinese Name Generator
古代人名生成器: Ancient Chinese Name Generator
秦朝到清朝 Historically Chinese name generator, from Qin to Qing dynasty
| Status | In development |
| Category | Tool |
| Author | Raycosine |
| Tags | Generator, name-generator, Procedural Generation |
| Languages | Chinese, Chinese (Simplified), Chinese (Traditional) |
| Accessibility | Color-blind friendly, High-contrast |
More posts
- v1.3->v2.0 大量数据和功能的扩充Jul 25, 2025
- v1.2->v1.3 增补数据、性别偏度估计、优化显示、问题修正Dec 09, 2024
- v1.3 附:性别偏度的说明和计算Dec 09, 2024
- v1.1->v1.2 数据和功能扩充Oct 21, 2024
- v1.2 附:此版本数据中的各朝代人名高频字词演变Oct 20, 2024
- v1->v1.1 一些微小的修订(单双名比例,按钮加载,姓名数据...Oct 09, 2024
- v1->v1.1 收录了更多朝代Oct 08, 2024
Comments
Log in with itch.io to leave a comment.
修订吐蕃人名和西夏人名的统称为“西部地区”。之前写的时候想的是西夏人名与没有加入的佉卢文和于阗文的人名,暂时忘记了吐蕃人名的归属。但吐蕃和西夏都不算西域,所以原来写的“西北及西域”是不对的。
不知道后续如何为分类命名,理论上这些都源自出土文献,但多朝代的数据集与名录也有部分来源出土文献,大约不能单独分类为“出土文献”。目前暂时就这两个,也还没有找到足够可用的非西部地区的非汉语音译名资料,所以暂时叫“西部地区”吧。有更合适的说法也可以告诉我。