v1.3 附:性别偏度的说明和计算
基于身份信息的预测是机器学习中比较常见的问题。对性别的预测有一定的应用,但也有一定的道德风险。
直接作为应用来说,要尽量避免偏见;但在消除数据集和训练手段的偏见上,gender prediction 本身又是很重要的工具之一,例如Word Embedding Debiasing,首先需要在向量空间中衡量词的性别化程度,再基于结果进行中性词中性化、性别指向明显的词等距化之类的去偏处理;Counterfactual Data Augmentation (CDA) 则对文本语料库执行旨在逆转偏见的文本转换,然后将其结果附加到原始语料库,以形成用于训练嵌入的偏见得到缓解的新语料库。
基于名字的性别预测,中文可能比字母表小而人名更长的表音文字稍微复杂一些。在只有名字的情况下,最好辅助字形、字音、字义等信息进行优化。
但对于古代人名数据集来说,最大的问题是数据偏差太大(原始数据的全名性别比基本为几十,加权后的大概在3~14之间)。如果作为二元分类问题,常见的模型和去偏手段效果都不太好。所以需要定义一个连续的性别偏度,将其作为回归问题。
目前的计算方法是多次加权和平均,加入了字形上的判断。由于数据集的限制,核心在于性别偏度的计算,目前所用的训练模型只是为了减少导入文件的大小和在纯前端部署的难度,在准确性上有一定取舍。
总的来说,个人认为预测功能是符合使用需要、在 AI ethics 上的益处大于其所可能有的问题的(同时也能反映 v1.2 开始的生成数据的性别比例和 1:1 还是比较接近的,并没有像原数据那样离谱)。当然,目前的结果在数值上并不十分准确,只能反映大概的性别化倾向,使用者需要加入自己的判断。
---
以下是性别偏度的定义和计算:
预设我们一开始有所有名字的字符串和对应的性别,分别记为name和gender。
那么数据一开始会是这样:
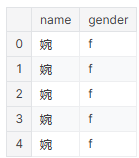
(包括重复的人名)
然后我们计算男女名字的比例 (记作r)。
对于每个name(有特殊标注的算作不同的name),计算作为女名和男名分别出现过的次数(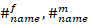 ),然后记录初始权重为
),然后记录初始权重为
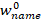 ,有
,有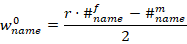
这个时候由于不同女名的总数少而权重高、不同男名的总数多而权重低,统计的次数分布会非常不均衡:
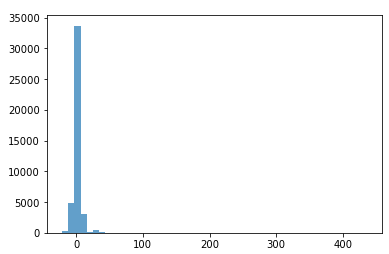
可以观察到绝大多数名字分布在权重为0的区域——这时候我们还没有区分中性名字和出现次数很少的名字;还有少数女名由于加权的原因获得了特别高的“出现次数”。
我们首先将出现次数很少的名字和中性名区分开,减轻分布过于集中的情况。
定义一个权重阈值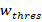 和出现次数的阈值
和出现次数的阈值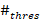 。如果对于一个名字,其初始权重小于,而作为女名/男名出现的次数小于,我们可以认为这是“出现次数很少的“名字而不是中性名。设这样的名字集合为
。如果对于一个名字,其初始权重小于,而作为女名/男名出现的次数小于,我们可以认为这是“出现次数很少的“名字而不是中性名。设这样的名字集合为
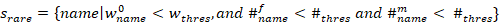
对于每个集合中的名字 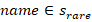 , 我们使用已有的第三方库fuzzychinese,找出名字数据集中与其字形相似的前
, 我们使用已有的第三方库fuzzychinese,找出名字数据集中与其字形相似的前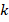 个名字,将其权重乘以相似值累加,再与该名字原有的权重叠加。其它名字的系数不变。得到中间步骤的权重为:
个名字,将其权重乘以相似值累加,再与该名字原有的权重叠加。其它名字的系数不变。得到中间步骤的权重为:
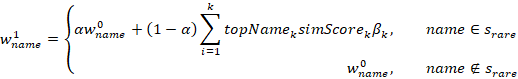
二个权重对比如图
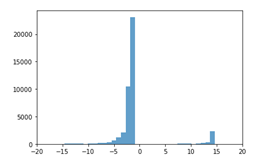
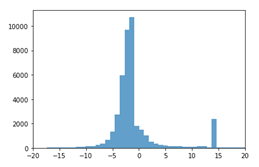
左图为在零周围的分布,右图为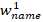 在零周围的分布
在零周围的分布
我们再将大部分权重和权重极高的女名分开,将后者统一赋值为1,前者分布到[-1,1)的区间。最后得到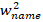 :
:
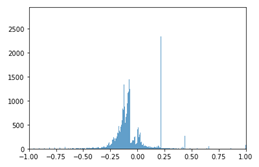
的分布虽然还是有“高权重女名”的存在,但更接近正态分布(如果分开处理名字的单字部分会更接近)。以此作为性别偏度。在目前的数据集中,性别偏度接近极值(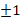 )、和中性化的名字分别有(随机取样):
)、和中性化的名字分别有(随机取样):
|
女名 |
男名 |
中性名 |
|
丽华 |
业 |
齿 |
|
仁淑 |
侃 |
龄先 |
|
从信 |
充 |
龄寿 |
|
从淑 |
兴 |
龙光 |
|
令仪 |
圭 |
龙喜 |
基于进行训练即可。
———
v1.3使用的是线性回归。逻辑很简单,计算预测值y=ax+b,a、b为模型参数。x为输入的名字变量,可以近似理解成一n*1的向量,n大约为几千,每行对应字库中的一个字,如名字里有这个字则记作1,否则记为0。对于大于一字的名字,每个字独立线性影响性别偏度,字的顺序不影响预测值。
虽以常识度之,大部分情况下末字的性别偏向更为明显,但如此划分则需要给名字各部分赋以不同的权重,难以斟酌。因此在实装时考虑使用的还是线性回归这个简单但表现也还可以的模型。(作者其实也训了 xgboost 之类“高级”一点的模型,但在目前 biased 的数据集上没有特别突出的优越性,而且从 Python 移植到 JavaScript 上有点麻烦,故现下不作考虑。)
Leave a comment
Log in with itch.io to leave a comment.